Yapay zekâ modellerinin temelini oluşturan sinir ağlarının sayısal ağırlıklarını depolamak söz konusu olduğunda, günümüzdeki büyük dil modelleri genellikle 16 veya 32 bitlik kayan noktalı sayılara dayanıyor. Ancak bu yüksek hassasiyet, yüzlerce gigabayta ulaşabilen büyük bellek ihtiyacı ve işlem sırasında karmaşık matris çarpımları nedeniyle ciddi hesaplama maliyetleri anlamına geliyor.
Microsoft’un Genel Yapay Zekâ (General AI) ekibi ise bu alanda ezber bozan bir adım attı. Araştırmacılar, yalnızca üç farklı ağırlık değeriyle (-1, 0 ve 1) çalışan yeni bir sinir ağı modeli geliştirdiklerini duyurdu. 2023 yılında yayımlanan önceki çalışmaların üzerine inşa edilen bu “üçlü” (ternary) mimari, modelin genel karmaşıklığını önemli ölçüde azaltırken, sıradan masaüstü işlemcilerde bile verimli şekilde çalışmasına olanak tanıyor.

Araştırmacılar, bu yeni sistemin ağırlık hassasiyetini büyük ölçüde düşürmesine rağmen, benzer boyuttaki açık kaynaklı ve tam hassasiyetli modellere yakın bir performans sergilediğini belirtiyor.
Ağırlıkları Hafifletme Çabası Yeni Değil
Model ağırlıklarını sadeleştirme fikri aslında yapay zekâ araştırmalarında yeni değil. Yıllardır araştırmacılar, sinir ağlarını daha küçük belleklerde çalıştırmak için “quantization” adı verilen sıkıştırma tekniklerini deniyor. Bu tekniklerin en uç örneklerinden biri, her ağırlığı yalnızca 1 bit ile temsil eden “BitNet” modelleri olmuştu.
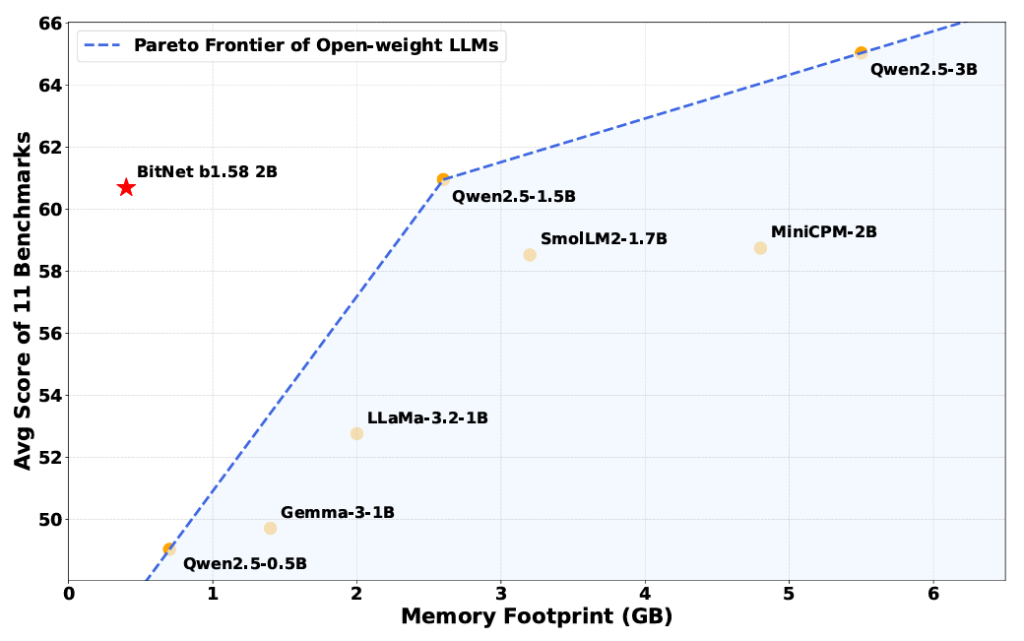
Microsoft’un yeni modeli BitNet b1.58b, bu kadar ileri gitmese de, ağırlıkları üç farklı değerle ifade eden “1.58 bitlik” sistemle çalışıyor (bu sayı, üç değeri ifade etmek için gereken ortalama bit miktarını gösteriyor: log(3)/log(2)). Araştırmacılar bu modeli, “ölçekli olarak eğitilmiş ilk açık kaynaklı, doğal 1-bit LLM” olarak tanımlıyor. Model, 4 trilyon token’lık veriyle eğitilmiş ve yaklaşık 2 milyar parametre içeriyor.
Buradaki “doğal” ifadesi kritik çünkü geçmişteki birçok quantization çalışması, daha önce yüksek hassasiyetle eğitilmiş modellerin sonradan sıkıştırılmasıyla yapılıyordu. Ancak bu yaklaşım, ciddi performans kayıplarına neden olabiliyordu. BitNet b1.58b ise baştan itibaren düşük bitli yapı üzerine inşa edilerek bu sorunu ortadan kaldırmayı hedefliyor.
Performans ve Verimlilikte Büyük Kazanç
Modelin sadeleştirilmiş ağırlık yapısı, yalnızca 0.4 GB bellekle çalışmasını sağlıyor. Bu değer, benzer boyuttaki diğer açık kaynaklı modellerin 2 ila 5 GB arasında değişen bellek ihtiyaçlarına göre oldukça düşük.
Ayrıca, BitNet b1.58b’nin çalışma sürecindeki işlemler, daha çok toplama gibi basit matematiksel işlemlere dayanıyor; bu da çarpma gibi yoğun kaynak gerektiren işlemlere duyulan ihtiyacı azaltıyor. Araştırmacılar, bu sayede modelin enerji tüketiminin benzer tam hassasiyetli modellere göre %85 ila %96 oranında daha düşük olduğunu belirtiyor.
Ancak bu başarılı sonuçlara rağmen, araştırmacılar modelin bu kadar düşük ağırlıkla neden bu kadar etkili çalıştığını tam olarak anlayabilmiş değil. “1-bit eğitimle ölçekli başarının neden işe yaradığını açıklayan teorik temeller hâlâ tam olarak anlaşılmış değil,” ifadesiyle daha fazla araştırmaya ihtiyaç olduğunu vurguluyorlar.
Uygun Fiyatlı Yapay Zekâ Mümkün mü?
Yüksek donanım ve enerji maliyetlerinin giderek daha büyük sorun hâline geldiği günümüzde, bu yeni yaklaşım önemli bir alternatif olabilir. Araştırmacılara göre mevcut “tam hassasiyetli” modeller, yüksek performans uğruna gereğinden fazla kaynak tüketen “kaslı arabalar” gibiyken; BitNet gibi sadeleştirilmiş sistemler, aynı yolu çok daha ekonomik bir şekilde alabilecek “kompakt arabalar” olabilir.